
Nestes post vamos tentar passar algumas dicas de como usar Expressão Regular usando Notepad ++. No dia a dia é muito comum para desenvolvedores fazerem modificações em massa, e acaba sempre usando a ferramenta de forma manual. Nosso objetivo é torna mais fácil e rápido as alterações.
Alguns detalhes que você deve cuidar para utilizar a ferramenta Notepad ++
Em todos os exemplos, use Localizar e substituir (Ctrl + H) para substituir todas as correspondências pela string desejada ou (sem string).
Certifique-se de que o botão de opção ‘Expressão regular’ esteja definido.
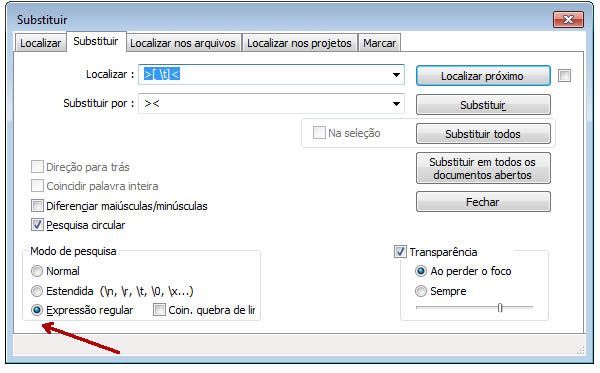
Veja também: 10 exemplos de Expressão regular como usar no notepad ++
1. Removendo espaços em branco
Como remover no Notepad++ espaços em branco nos textos e códigos. Neste exemplo, substituímos os espaços em branco e as guias entre os pares de strings ‘> <‘
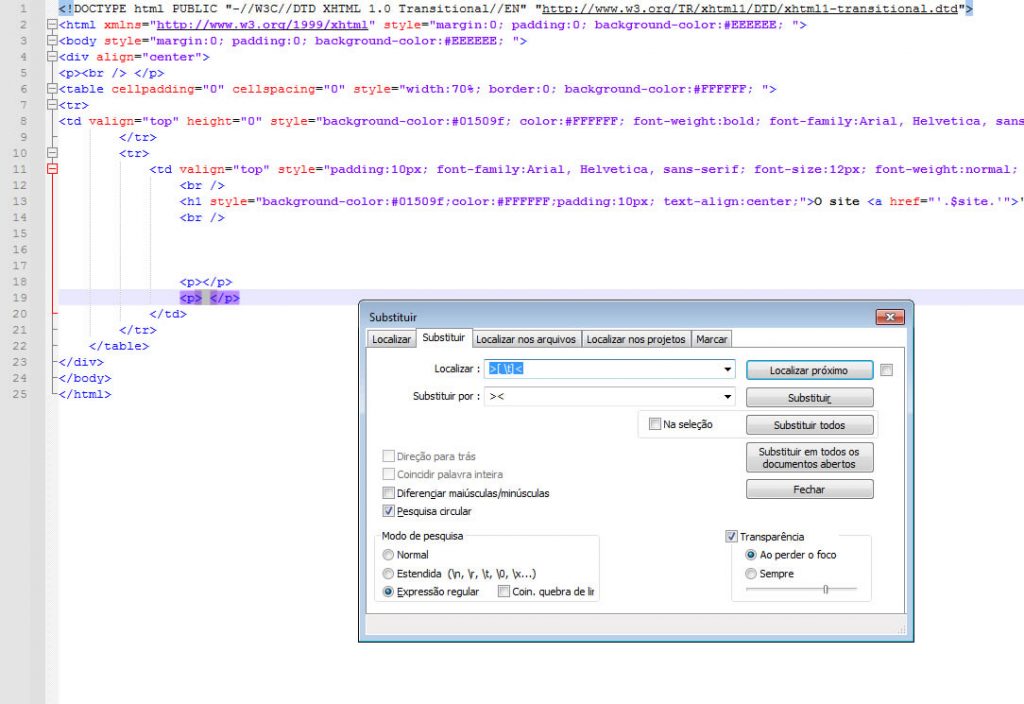
Veja o texto de Expressão Regular: https://rubular.com/r/GKTqfI34My78LT
Expressão de correspondência Regex: (Desative a quebra de linha para que você possa vê-la mesclada em uma linha)
>[ \t]<
- A expressão regular
>[ \t]<procura por uma sequência específica de caracteres:- Um caractere
>seguido imediatamente por: - Um espaço ( ) ou uma tabulação (
\t), seguido imediatamente por: - Um caractere
<.
- Um caractere
Em outras palavras, ela identifica padrões onde há um > seguido de um espaço ou tabulação, e depois um <.
No campo Substituir use:
><
2. Insira uma nova linha para cada linha de texto
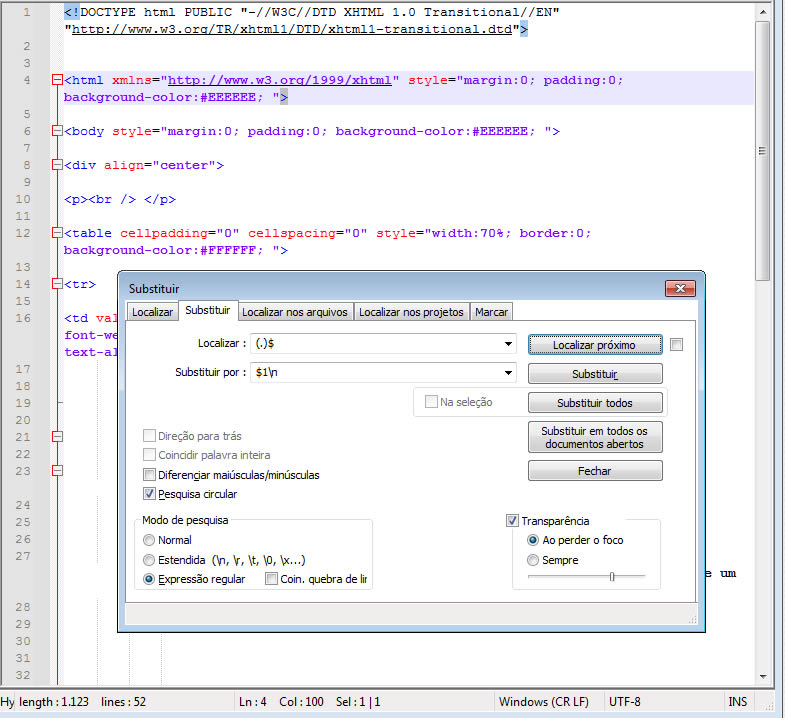
Veja o teste na expressão regular: https://rubular.com/r/VSwfp0CvIV4RJO
Campo Localizar:
(.)$
(): Os parênteses criam um grupo de captura . Isso significa que qualquer coisa que corresponda ao padrão dentro dos parênteses será “capturada” para uso posterior (no caso, na substituição)..: O ponto (.) é um caractere curinga na expressão regular. Ele corresponde a qualquer caractere único , exceto quebras de linha (por padrão).$: O cifrão ($) é um âncora que corresponde ao final de uma linha . Ele indica que o padrão deve estar localizado exatamente no fim da linha.
Portanto, (.)$ significa: “Encontrar o último caractere de cada linha”.
Campo Substituir:
$1\n
$1: Refere-se ao primeiro grupo de captura (o que foi capturado pelos parênteses()na expressão regular). Neste caso, é o último caractere de cada linha.\n: Representa uma quebra de linha (newline). No Notepad++,\ninsere uma nova linha após o caractere capturado.
Portanto, $1\n significa: “Substituir o último caractere da linha pelo próprio caractere seguido de uma quebra de linha”.
3. Removendo linhas em branco
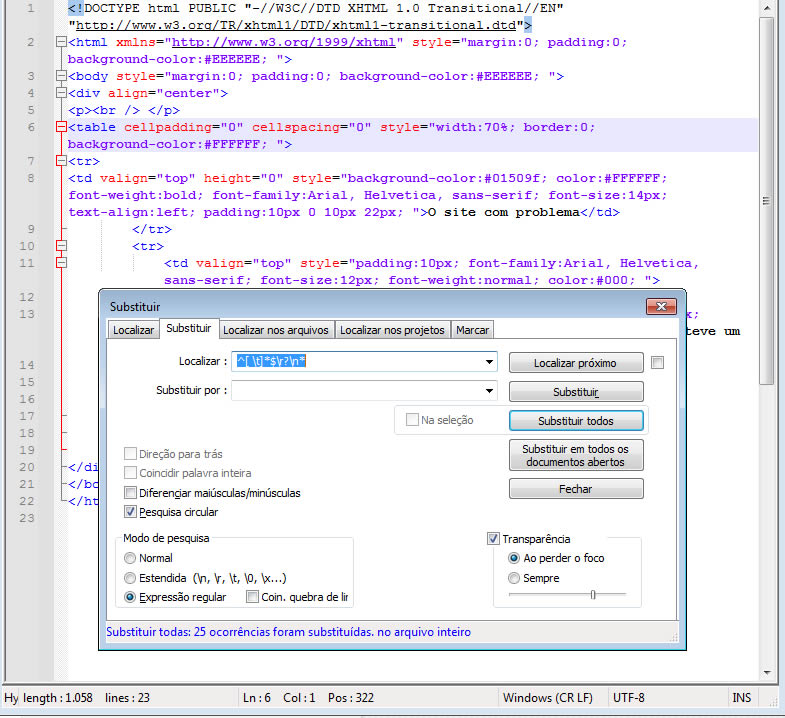
Veja o teste na expressão regular: https://rubular.com/r/q09H3O3TBSKbWo
Campo Localizar:
^[ \t]*$\r?\n*
^: Este símbolo é uma âncora que corresponde ao início de uma linha .[ \t]*:[ \t]: É uma classe de caracteres que corresponde a espaços () ou tabulações (\t) .*: É um quantificador que significa “zero ou mais ocorrências”. Portanto,[ \t]*corresponde a zero ou mais espaços ou tabulações.
$: Este símbolo é outra âncora que corresponde ao final de uma linha .\r?\n*:\r?: Corresponde a um retorno de carro (\r) opcionalmente (o?indica “zero ou uma ocorrência”).\n*: Corresponde a zero ou mais quebras de linha (\n).
Portanto, ^[ \t]*$\r?\n* significa: “Uma linha que contém apenas espaços ou tabulações (ou nada) do início (^) ao fim ($) da linha, seguida por uma quebra de linha opcional (\r?\n*).”
Campo Substituir:
Ao substituir por “nada” (deixando o campo de substituição vazio), você está removendo completamente as linhas correspondentes .
4. Quebrar a lista separada por vírgula em linha
Substitua a vírgula de uma lista por uma quebra de linha.
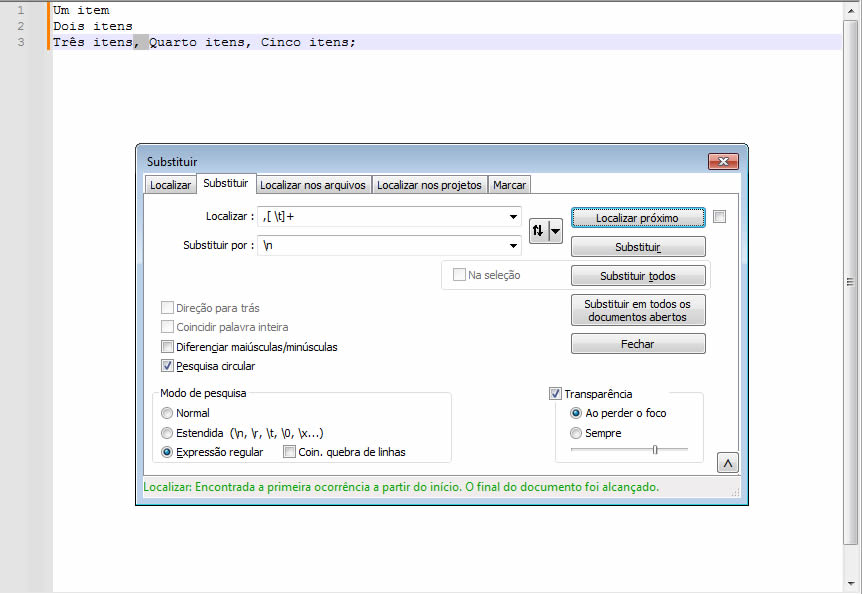
Veja o teste de expressão regular: https://rubular.com/r/O0rTGd84xjQqhB
Campo Localizar:
,[ \t]+
,
- A vírgula (
,) é um caractere literal. Ela corresponde exatamente ao caractere vírgula no texto.
[ \t]+
[ \t]: É uma classe de caracteres que corresponde a espaços () ou tabulações (\t) .+: É um quantificador que significa “uma ou mais ocorrências”. Portanto,[ \t]+corresponde a um ou mais espaços ou tabulações consecutivos .
Portanto, ,[ \t]+ significa: “Uma vírgula seguida de um ou mais espaços ou tabulações.”
Campo Substituir:
\n
\nrepresenta uma quebra de linha (newline). No Notepad++, isso insere uma nova linha no lugar do padrão encontrado.
Portanto, ao substituir ,[ \t]+ por \n, você está: Removendo a vírgula e os espaços/tabulações subsequentes. Inserindo uma quebra de linha no lugar.
5. Remova palavras duplicadas
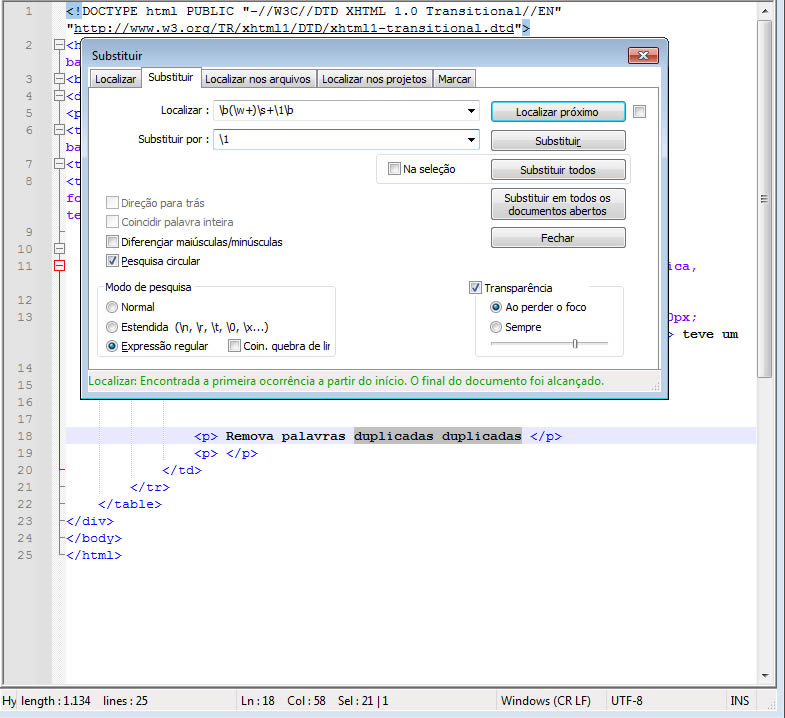
Campo Localizar:
\b(\w+)\s+\1\b
\b: É uma âncora de limite de palavra . Ela garante que a correspondência ocorra exatamente nos limites de uma palavra (ou seja, entre o início/fim de uma palavra e caracteres não alfanuméricos).(\w+):\w: Corresponde a qualquer caractere alfanumérico (letras, números ou sublinhados_).+: Quantificador que significa “uma ou mais ocorrências”. Portanto,\w+corresponde a uma palavra inteira.(): Os parênteses criam um grupo de captura . Isso permite que a palavra correspondida seja referenciada posteriormente na expressão regular.
\s+:\s: Corresponde a qualquer caractere de espaço em branco (espaços, tabulações, quebras de linha, etc.).+: Quantificador que significa “uma ou mais ocorrências”. Portanto,\s+corresponde a um ou mais espaços em branco.
\1:\1: Refere-se ao primeiro grupo de captura (a palavra capturada por(\w+)). Isso garante que a segunda palavra seja igual à primeira.
\b: Outra âncora de limite de palavra, garantindo que a correspondência termine exatamente no final da segunda palavra.
Portanto, \b(\w+)\s+\1\b significa: “Uma palavra seguida de um ou mais espaços e depois a mesma palavra novamente.”
Campo Substituir:
\1
\1: Refere-se ao primeiro grupo de captura , ou seja, a palavra capturada pela expressão(\w+).
Portanto, ao substituir \b(\w+)\s+\1\b por \1, você está: Mantendo apenas a primeira ocorrência da palavra. Removendo a duplicação e os espaços subsequentes.
6. Deixar apenas a primeira palavra de cada linha
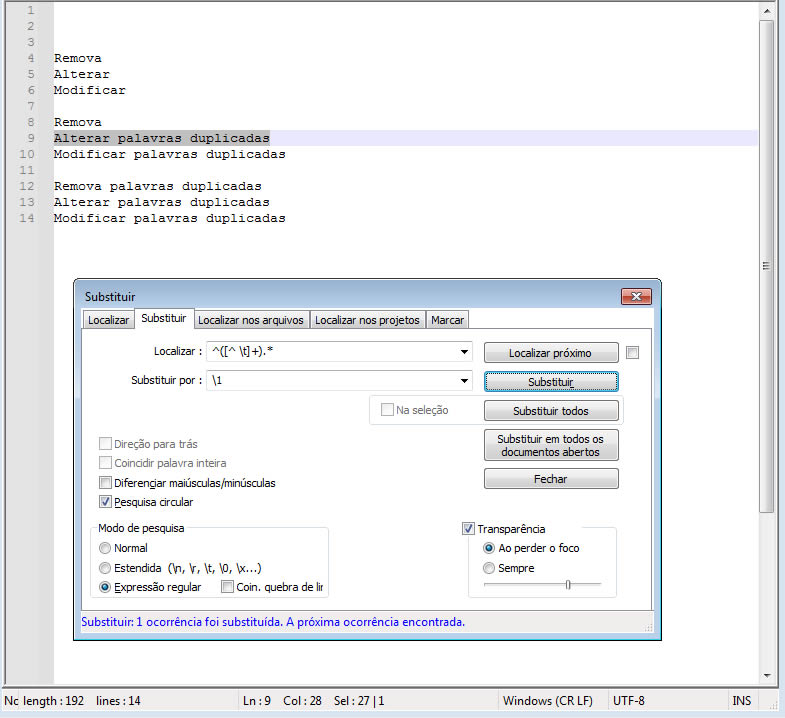
Campo Localizar:
^([^ \t]+).*
^: É uma âncora que corresponde ao início da linha .([^ \t]+):[ \t]: É uma classe de caracteres negada (devido ao^dentro dos colchetes) que corresponde a qualquer caractere que não seja um espaço ( ) ou tabulação (\t) .+: Quantificador que significa “uma ou mais ocorrências”. Portanto,[^ \t]+corresponde à sequência de caracteres contíguos que formam a primeira palavra da linha (ou seja, tudo até o primeiro espaço ou tabulação).(): Os parênteses criam um grupo de captura . Isso permite que a primeira palavra seja referenciada posteriormente na substituição.
.*:.: Corresponde a qualquer caractere (exceto quebras de linha).*: Quantificador que significa “zero ou mais ocorrências”. Portanto,.*corresponde ao restante da linha após a primeira palavra.
Portanto, ^([^ \t]+).* significa: “Do início da linha, capture a primeira palavra (sequência de caracteres sem espaços ou tabulações), e depois ignore todo o restante da linha.”
Campo Substituir:
\1
A mesma ação do item anterior.
7. Deixar apenas a última palavra de cada linha
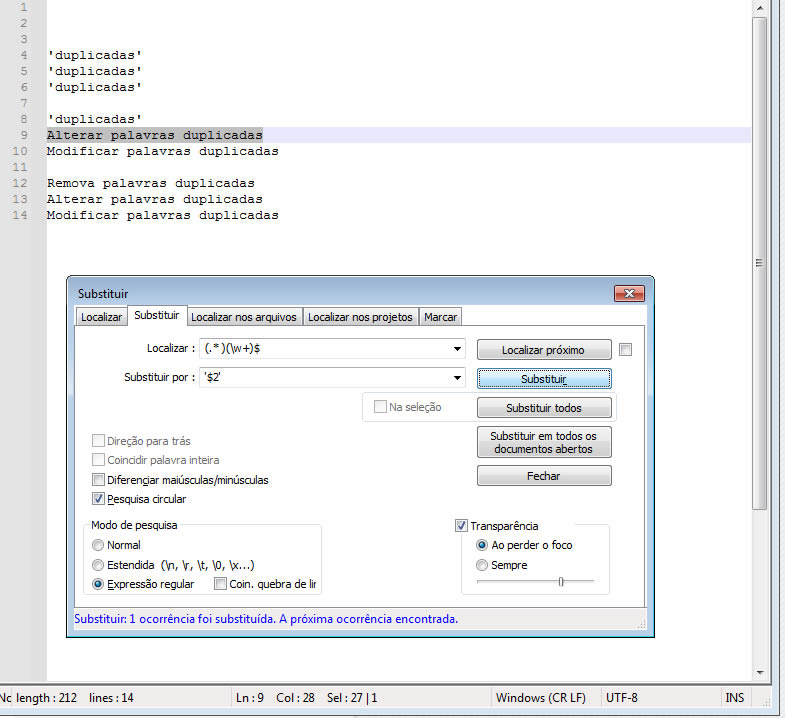
Neste exemplo deixamos apenas a última palavra e colocamos entre aspas. bastas tirar as aspas no código do campo Substituir se não for necessário.
Campo Localizar:
(.* )(\w+)$
(.*):.: Corresponde a qualquer caractere (exceto quebras de linha).*: Quantificador que significa “zero ou mais ocorrências”. Portanto,.*corresponde a todo o conteúdo da linha até o último espaço .(): Os parênteses criam um grupo de captura . Isso permite que todo o conteúdo antes do último espaço seja referenciado posteriormente (neste caso, como$1).
(\w+)$:\w: Corresponde a qualquer caractere alfanumérico (letras, números ou sublinhados_).+: Quantificador que significa “uma ou mais ocorrências”. Portanto,\w+corresponde à última palavra da linha (sequência contígua de caracteres alfanuméricos).$: É uma âncora que corresponde ao final da linha .(): Os parênteses criam outro grupo de captura . Isso permite que a última palavra seja referenciada posteriormente (neste caso, como$2).
Portanto, (.* )(\w+)$ significa: “Capture todo o conteúdo da linha até o último espaço (grupo 1), e depois capture a última palavra da linha (grupo 2).”
Campo Substituir:
'$2'
$2: Refere-se ao segundo grupo de captura , ou seja, a última palavra da linha capturada pela expressão(\w+)$.': Adiciona aspas simples ao redor da última palavra.
Portanto, ao substituir (.* )(\w+)$ por '$2', você está: Ignorando todo o conteúdo da linha exceto a última palavra. Colocando a última palavra entre aspas simples.
8. Substitua todas as linhas duplicadas por uma única linha
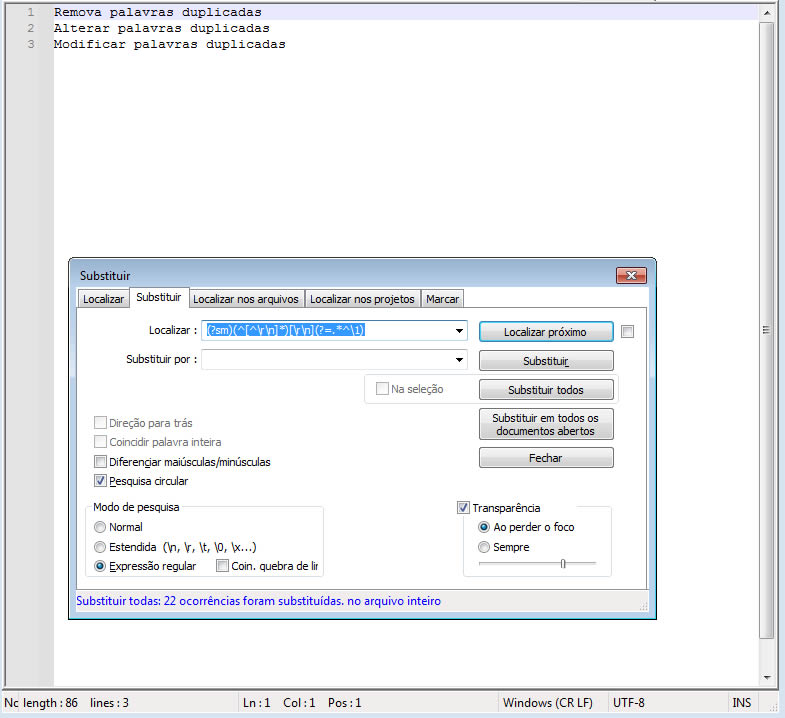
Campo Localizar:
(?sm)(^[^\r\n]*)[\r\n](?=.*^\1)
(?sm):s: Ativa o modo “single-line”, onde o ponto (.) corresponde a todos os caracteres , incluindo quebras de linha.m: Ativa o modo “multi-line”, onde os âncoras^e$correspondem ao início e fim de cada linha , e não apenas ao início e fim do texto inteiro.
(^[^\r\n]*):^: Âncora que corresponde ao início da linha .[^\r\n]*: Corresponde a qualquer sequência de caracteres que não sejam quebras de linha (\rou\n).(): Os parênteses criam um grupo de captura . Isso permite que a linha inteira seja referenciada posteriormente (como$1).
[\r\n]:- Corresponde à quebra de linha após a linha capturada. Pode ser
\r\n(Windows),\n(Unix/Linux) ou\r(Mac antigo).
- Corresponde à quebra de linha após a linha capturada. Pode ser
(?=.*^\1):(?=...): É uma asserção lookahead (ou “lookahead positivo”). Ela verifica se algo existe à frente na string, mas não o consome..*: Corresponde a qualquer número de caracteres (incluindo quebras de linha, devido ao modos).^: Âncora que corresponde ao início de uma linha .\1: Refere-se ao primeiro grupo de captura , ou seja, a linha capturada anteriormente.
Portanto, (?sm)(^[^\r\n]*)[\r\n](?=.*^\1) significa: “Capture uma linha inteira (sem as quebras de linha) e sua quebra de linha subsequente, mas apenas se essa linha aparecer novamente mais adiante no texto.”
Campo Substituir:
(vazio)
- Ao substituir por “nada” (deixando o campo de substituição vazio), você está removendo completamente as linhas duplicadas encontradas pela regex.
9. Insira todo o texto em uma única linha (minificar o HTML no Notepad sem plugin)
Para quem gostaria de minificar o HTML usando o Notepad++ esta é uma grande dica de uso:
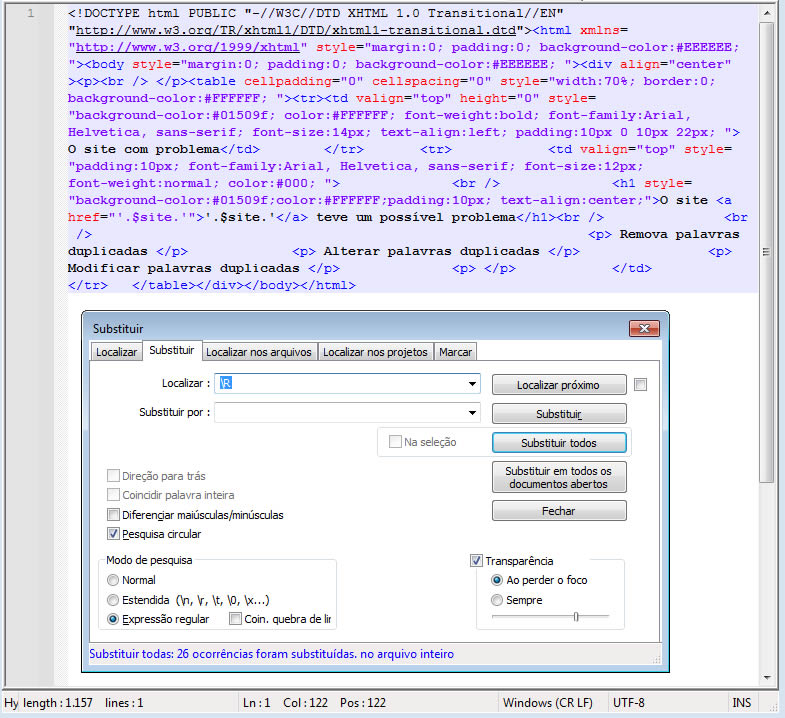
Depois de executado você pode usar o item 3 para limpar os espaços em excesso.
Campo Localizar:
\R
\R: É um atalho especial no Notepad++ que corresponde a qualquer tipo de quebra de linha, independentemente do sistema operacional:\r\n: Quebra de linha no formato Windows.\n: Quebra de linha no formato Unix/Linux.\r: Quebra de linha no formato Mac antigo.
Portanto, \R significa: “Qualquer tipo de quebra de linha.”
Campo Substituir:
(vazio)
10. Substitua a primeira linha no texto
https://rubular.com/r/CCDSaAMzkSLqdj
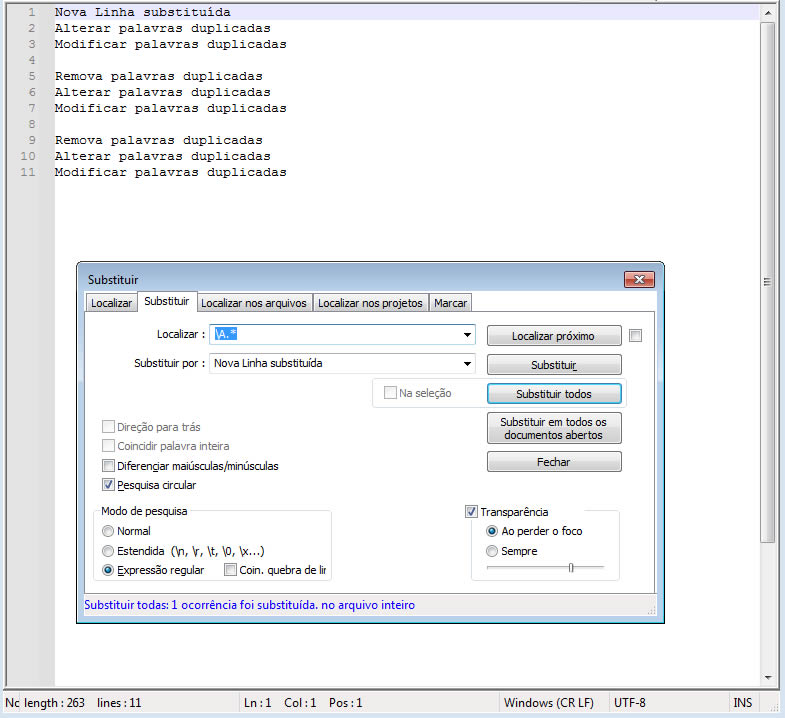
Campo Localizar:
\A.*
\A:- É uma âncora que corresponde ao início absoluto do arquivo (antes de qualquer caractere, incluindo quebras de linha). Diferentemente de
^, que pode corresponder ao início de qualquer linha em modo multi-line,\Asempre se refere ao início do arquivo.
- É uma âncora que corresponde ao início absoluto do arquivo (antes de qualquer caractere, incluindo quebras de linha). Diferentemente de
.*:.: Corresponde a qualquer caractere (exceto quebras de linha).*: Quantificador que significa “zero ou mais ocorrências”. Portanto,.*corresponde a todos os caracteres na primeira linha, até o final dela.
Portanto, \A.* significa: “Do início do arquivo, capture toda a primeira linha.”
Campo Substituir:
(vazio)
11. Remova caracteres indesejados
Podemos querer remover todos os caracteres especiais e deixar letras e números. Para caracteres alfanuméricos, pontos finais, dois pontos/ponto, vírgula, espaços, tabulações, novas linhas, é melhor você testar antes de executar, utilize esta ferramenta:
https://rubular.com/r/WbMCcWymgmRv5S
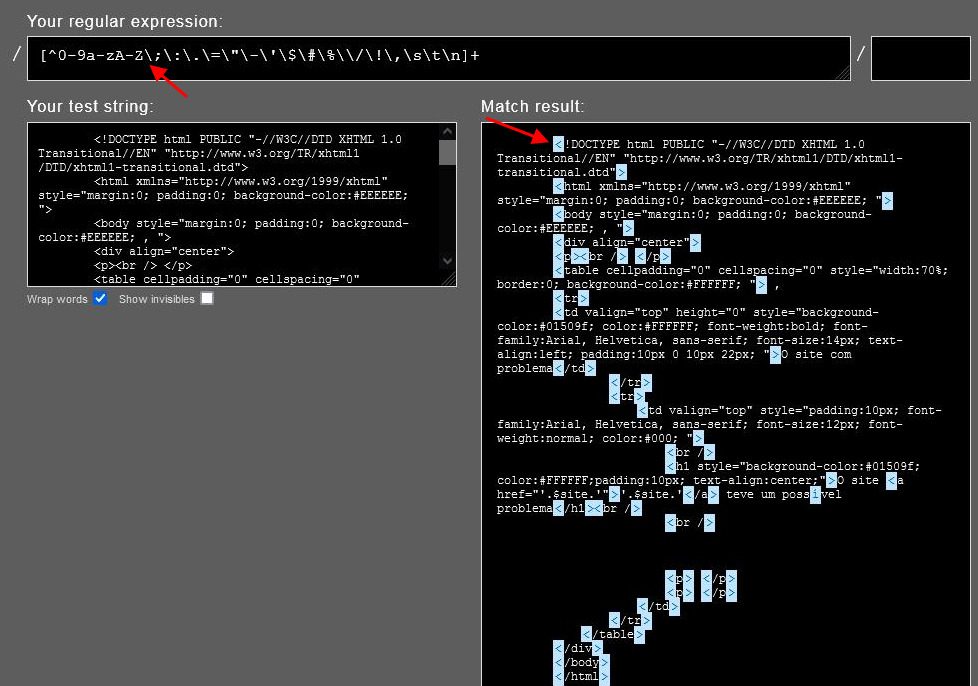
No exemplo do link, tentei retirar apenas os caracteres < e >. Utilizei o escape ( contra barra \ ) para não pegar os caracteres que eu não queria retirar do código.
[^0-9a-zA-Z\;\:\.\=\"\-\'\$\#\%\\/\!\,\s\t\n]+
No final da expressão regular o \s – corresponde a qualquer caractere de espaço em branco; \t – indica o Tab; \n – indica quebra de linha. Você pode substituir os 3 por [:space:] (Corresponde a todos os caracteres de espaço em branco, incluindo espaços, tabulações e quebras de linha).
Para palavras com acentuação você pode usar à-úÀ-Ú
[^0-9a-zA-Zà-úÀ-Ú\;\:\.\=\"\-\'\$\#\%\\/\!\,\s\t\n]+
Na imagens abaixo é um exemplo de como retirar todos os caracteres especiais e deixar apenas letras e números.
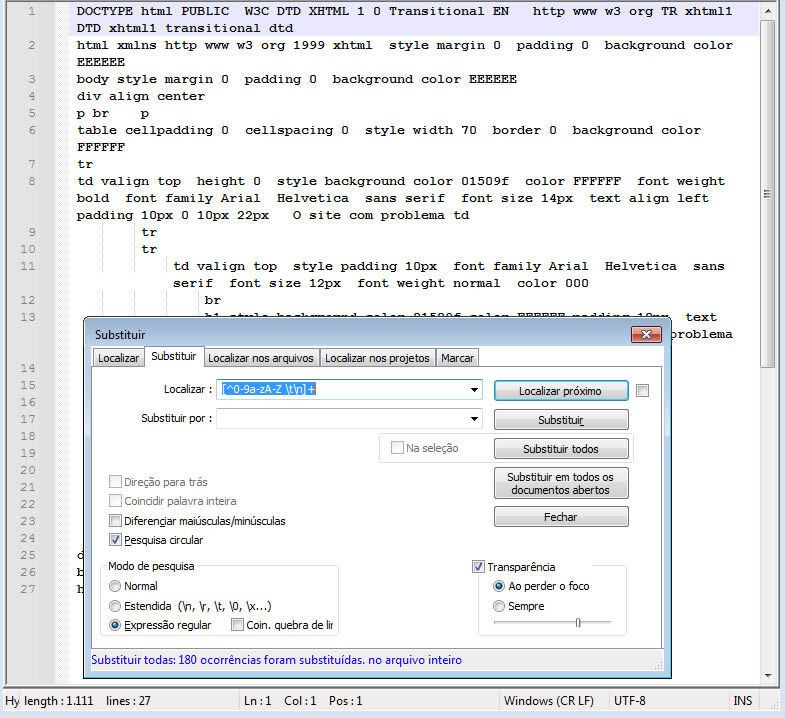
Campo Localizar:
[^0-9a-zA-Z \t\n]+
[^...]:- Os colchetes com o acento circunflexo (
^) dentro criam uma classe de caracteres negada . Isso significa que a regex corresponde a qualquer caractere que NÃO esteja listado dentro dos colchetes .
- Os colchetes com o acento circunflexo (
0-9:- Corresponde a qualquer dígito numérico de
0a9.
- Corresponde a qualquer dígito numérico de
a-zA-Z:- Corresponde a qualquer letra do alfabeto, tanto minúsculas (
a-z) quanto maiúsculas (A-Z).
- Corresponde a qualquer letra do alfabeto, tanto minúsculas (
- (espaço):
- Corresponde ao caractere de espaço literal.
\t:- Corresponde ao caractere de tabulação horizontal.
\n:- Corresponde à quebra de linha (newline).
+:- Quantificador que significa “uma ou mais ocorrências”. Isso faz com que a regex capture sequências contíguas de caracteres que não sejam alfanuméricos, espaços, tabulações ou quebras de linha.
Portanto, [^0-9a-zA-Z \t\n]+ significa: “Uma ou mais ocorrências de qualquer caractere que NÃO seja um número, letra, espaço, tabulação ou quebra de linha.”
Campo Substituir: (Digite a tecla espaço para não deixar as palavras juntas)
(vazio)
12. Converter palavras para minúscula, exceto para siglas e abreviações
Podemos querer garantir que o texto seja convertido em letras minúsculas, exceto para acrônimos e abreviaturas que são mantidos em letras maiúsculas.
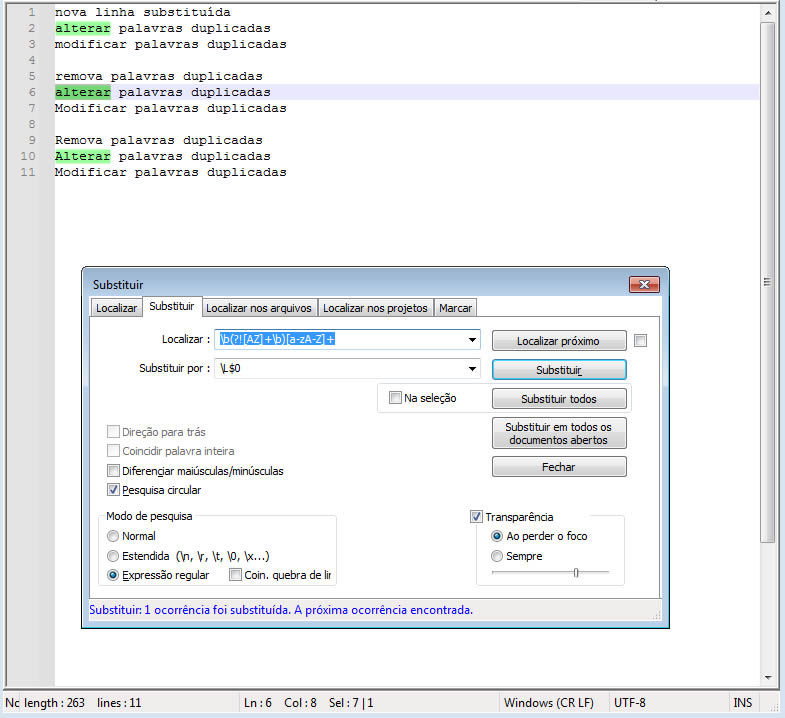
Campo Localizar:
\b(?![AZ]+\b)[a-zA-Z]+
\b:- É uma âncora de limite de palavra . Ela garante que a correspondência ocorra exatamente nos limites de uma palavra (ou seja, entre o início/fim de uma palavra e caracteres não alfanuméricos).
(?![A-Z]+\b):?!: É uma asserção lookahead negativa . Ela verifica se algo não existe à frente na string.[A-Z]+: Corresponde a uma ou mais letras maiúsculas consecutivas.\b: Garante que a sequência de letras maiúsculas termine exatamente no limite de uma palavra.- Portanto,
(?![A-Z]+\b)significa:- “Certifique-se de que a palavra atual não seja composta exclusivamente por letras maiúsculas .”
[a-zA-Z]+:[a-zA-Z]: Corresponde a qualquer letra, tanto minúscula (a-z) quanto maiúscula (A-Z).+: Quantificador que significa “uma ou mais ocorrências”. Portanto,[a-zA-Z]+corresponde a uma palavra inteira composta por letras.
Portanto, \b(?![A-Z]+\b)[a-zA-Z]+ significa: “Uma palavra inteira (limitada por \b) que não seja composta exclusivamente por letras maiúsculas .”
Campo Substituir:
\L$0
\L:- É um modificador que converte todos os caracteres subsequentes na substituição para letras minúsculas .
$0:- Refere-se à correspondência completa encontrada pela expressão regular (ou seja, a palavra inteira).
Portanto, \L$0 significa: “Converta a palavra inteira encontrada para letras minúsculas.”
Veja também: 10 exemplos de Expressão regular como usar no notepad ++
Entenda alguns caracteres usados na Expressão Regular:
\n
quebra de linha
\t
Tab
\d
Um dígito no intervalo de 0-9 (um número)
\D
Não é um dígito. Qualquer coisa que não seja um número (incluindo espaços).
\l
Uma letra minúscula.
OBSERVAÇÃO: isso retornará a “um caractere de palavra” se a opção de pesquisa “Match case” estiver desativada.
\L
Não é uma letra minúscula.
\u
Uma letra maiúscula.
\U
Não é uma letra maiúscula.
\w
Um caractere de palavra, que é uma letra, dígito ou sublinhado. Isso parece não depender do que o componente Scintilla considera como caracteres de palavras. O mesmo que [[:palavra:]].
\W
Não é um caractere de palavra.
\s
Um caractere de espaçamento: contagem de espaço, EOLs e tabulações.
\S
Não é um espaço.
\h
Espaçamento horizontal. Isso corresponde apenas ao espaço, tabulação e alimentação de linha.
\H
Não é espaço em branco horizontal.
\v
Espaço em branco vertical.
\V
Não é espaço em branco vertical
$
Aplica-se apenas ao caractere no final de uma linha. (ex. ‘!$’ substituiria todos os pontos de explicação no final de uma linha.)
^
Online aplica-se ao caractere no início de uma linha (ex. ‘^<p>’ substituiria qualquer ‘<p>’ no início de uma linha.)



Excelente artigo. Era exatamente o que eu procurava.
Obrigado!
Obrigado Marcos, é sempre bom ter um feedback dos leitores!
Ótimo conteúdo.
Porém, tenho uma situação que não consegui imaginar uma maneira de resolver. Tenho o texto:
<book navtitle="Propriedades_Por_Empresa_do_Módulo_Fiscal"
desse texto queria substituir o _ por um espaço, mas o texto é só um dos que tem esse caractere, existem vários outras linhas com essa característica que preciso substituir apenas o _ pelo espaço.
Tens uma sugestão?
Olá Gilmar
Então, é só vc manter selecionado o item: Expressão Regular do Notepad ++
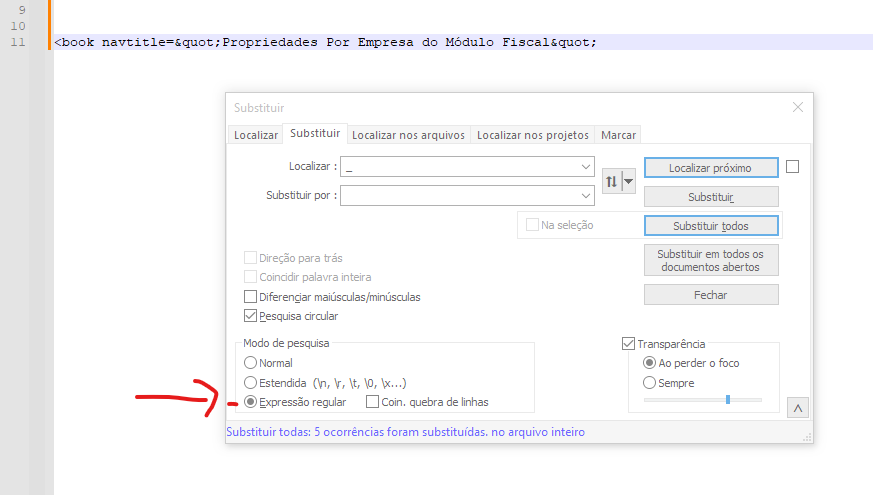
Coloca o caracter que vc quer localizar _ e dá um espaço em branco no item substituir:
https://rubular.com/r/i2jGn5IFAnQe8q
Boa tarde,
Consigo substituir todos os strings dentro de todo cadastro que contenha “MDF” no ????
segue exemplo de um cadastro:
##%00 – MATERIAIS BASSANI%MDF%DURATEX%CARVALHO AVELA
%DURATEX_5A639F2E
1
1
0
1
1
0
0.8
0
0
0
0
0
0
1
1
1
1200
1200
0
0
1 1 1
0.1 1 1 1
0.1
1 1 1
0
%CARVALHOAVELA_5528442F
6
NONE
NONE
%CARVALHO AVELA
NONE
NONE
0
0
1
0
0
0
1
1
4
2.7499
1.84009
0
NONE
4
0.05
0.05
0
1
1 1 1
0
NONE
0
Não entendi o que você quer mudar.
Mas basta Pressione Ctrl + H para abrir a janela “Substituir”.
No campo “Localizar”, insira o seguinte:
MDF
No campo “Substituir por”, insira a string q vc quer incluir, nosso caso:
EXEMPLO
o texto foi todo desconfigurado e faltando palavras… tudo oq estava entre “”, sumiu ao publicar… ficou sem sentido mesmo…
mas vou tentar explicar…
tenho um cadastro estruturado dentro de “material” “/material”, e dentro de cada um desse que contiver “MDF” no nome, gostaria de substituir o valor do campo “density” “/density”
deu pra entender?
Jefferson, teria que me mostrar os dados brutos para poder entender o que você quer modificar e em que contexto.
Ainda não entendi o que você quer fazer…
Olá, tudo bem? é possivel fazer esse tipo de alteração?
preciso inserir um valor de |0,01| nesse campo x (informei x para identificar o campo, mas o valor é = 0). mas ele só pode ser atribuído em linhas que inicia com |C190|020|. segue exemplo.
|C190|000|5102|18,00|84,19|84,19|15,15|0|0|0|0||
|C190|020|5102|18,00|35,44|35,44|6,38|0|0|x|0||
|C190|040|5102||4,49|0|0|0|0|0|0||
Olá
Eu não entendi muito bem o que vc quer fazer, vou te passar um exemplo e vc pode adaptar ao teu contexto.
Vc pode usar esta expressão regular:
(^\|C190\|020\|.*?\|)x(\|0\|\|)Explicação:
^ → Início da linha.
\|C190\|020\| → Garante que a linha começa com |C190|020|.
.*? → Captura qualquer sequência de caracteres de forma não gulosa até o próximo padrão.
\| → Garante que estamos capturando até o próximo campo.
x → Localiza o campo que contém x.
(\|0\|\|) → Captura a parte final |0||, garantindo que a substituição ocorra no lugar certo.
Abra no notepad ++, no campo Localizar, insira a expressão regular
(^\|C190\|020\|.*?\|)x(\|0\|\|)No campo Substituir por, insira:
\1 0,01\2Marque a opção Expressão regular.
Clique em Substituir Tudo.
Isso substituirá x por 0,01 somente nas linhas que começam com |C190|020|.